Rationale
- Easier to migrate (from non-high-available to HA)
- Store/Fetch small files
- More familiar to programmers
- Reduce number of servers
Lock
- Coarse-grained
- Hold for hours or days
- Lock-acquisition rate weakly related to client transaction rate
- Rare acquisition ->Temp lock server unavailability -> No big deal
- Should not lost lock when lock server reboot
System Structure
- Client + Lib (Link) <-> Server (5 node)
- Chubby servers
- called replicas
- elect a master
- ask any replicas where the master is
- all replicas maintain identical database
- Only master read/write
- ack write after majority write
- read by master only
- Add new replica is one does not recover after a few hours
Files
- Name
- ex:
/ls/foo/wombot/pouch- ls: common prefix (lock service)
- foo: name of a Chubby cell
- special name:
local(local chubby cell)
- special name:
- ex:
- Operations
- Only whole file read
- No moving files from one directory
- (may served by different Chubby master)
- No soft/hard link
- Ephemeral Node (tmp files)
- Metadata ^a9d075
- instance number: greater than any previous with same name
- content generation (files only): change when file are written
- lock generation number: increase when lock
free->hold - ACL generation number: increase when ACL name change
- 3 ACL Name
- Checksum
- File handle ^e25fcd
- Check digit (No forging handle)
- Sequence number (if handle generate by previous master?)
- Mode (to recreate handle when crashed)
Lock
- Every file is a read-write lock
- Not mandatory locks
- Process without lock can still access file
- (similar to mutex lock in pthread)
- Need write permission for read lock
- to prevent blocking writer
- Lock acquiring and request can be out of order
- Need seq num => expensive 😢
- Sequencer
- contains
name of lock, lock generation number, mode - client request sequencer after lock acquisition
- send sequencer with request
- server reject if sequencer is not valid
- if holder fail, server wait
lock-delaybefore next lock
- contains
Events
- Client can subscribe events when creating a handle
- file modified, child node added …
Example: Primary Election
- All candidates open a lock file and acquire
- One succeed -> Write address to lock file
- Other notified and read
Caching
- When update a file
- Master invalidate all clients
- Wait for ACK (next
KeepAlive)- Mark file
uncachable
- Mark file
- Proceed to modify the file
- Cache data, meta-data, open handles, (Locks)
Session
- Client request a new session
- end when explicitly terminates or idle
- Lease, extend when
- creation of the session
- master fail-over
- responds to a
KeepAlive- Master block until previous lease is close to expiring (long-poll)
- return early when an event or invalidation need to be delivered
- Lease timeout expires -> client in
jeopardy- clear and disable cache
- Wait grace period, (try exchange
KeepAlive)
Fail Over
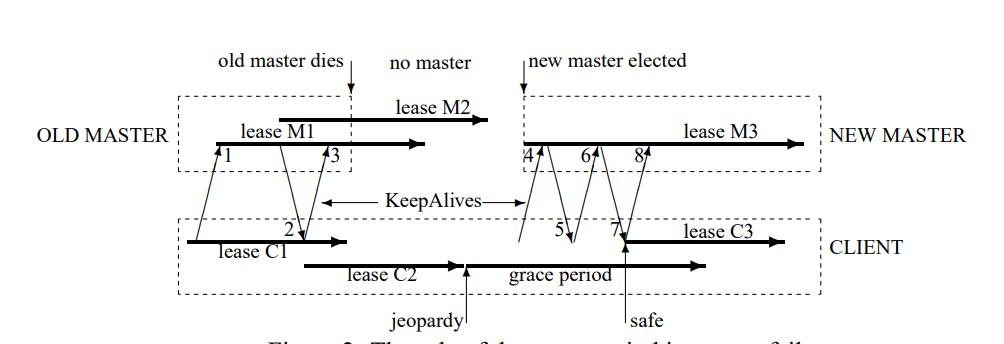
- 1~3 - Normal Keep Alive
- Server Fail, no keep alive reply
- Client approx lease timeout, enter jeopardy
- New server up, choose conservative (longest) lease
- emit
fail-over, clear all client cache
- emit
- 4 - Client send keep alive
- 5 - Server reject because invalid epoch
- 6 - Client retry
- 7 - Server reply, client extend lease
Performace
Proxies
- Setup proxy servers to serve
readandKeepAlive
Partitioning
- N partitions, each with a master and replicas
- Node
D/Cin directory D will be stored on- Partition number
hash(D) mod N
- Partition number
Misc.
Mostly use as name service
stupid developers => Aggressive caching
Lack of quotas => implement quotas (256k)
Cannot implement publish/subscribe (inefficient)
How could a client learn that another client has failed?
In Class
- High influential system in Google
- Influential outside - ZooKeeper etc
- Practical issues that arise
- at scale
- Use cases - example services that need consensus
What is Chubby
- Lock as a highly-available service
- Distributed coordination service
- Share small amount of data
What is ZooKeeper
- Opensource chubby
- no locks
- no
open/close - No blocking operations
- coordination service for dev to implement own primitives
Why not a Paxos library instead
- + Completely General
- Write service as state machine
Lock service-why
- + Easier to add incrementally when service needs availability & scale
- Become leader <-> acquire exclusive lock
- + Need mechanism to advertise results
- Publicize small amount of data
- + Lock are familiar
- + Availability-separation of client service from lock service failures
Use Cases?
- Leader election
- Configuration - Rendezvous
- Group membership
- Name server
- Meta-data (GFS)
- Barriers
- Locks-partitioning
- Publish-subscribe
- Not well with Chubby
- Well with ZooKeeper
Specialized system instead of general
Workload
- Scalability (thousands of clients)
- mostly read
- -> cache data on clients
Goal
- Intuitive consistent caching
- Linearizable: guarantee about single object
- writes appear instantaneous
- after completion, later reads return value of that write (or later write)
- later reads return that value or of later write
- Linearizable: guarantee about single object
- Security, access control
- Performance => not as important
- Availbility
Coarse-grain locks (v.s. fine-grain)
- Lock acquisition rate « client $\times$ action rate
- OK if lock server sometimes fails, master fail-over
- transparent to our client
- small delay
- But do not lose locks on lock server failures
System Structure
Cell
- Find master?
- ask any replica -> redirect to master
- Where to locate replicas?
- local, but diff-racks
- How to pick master?
- consensus protocol
- election, vote => “master lease”
Clients
- Writes?
- to master
- send to all replicas
- wait ack, before sending ack to client
- Read?
- to master
- Implication for master?
- bottleneck
Details Why is master lease needed?
- Problem with reading only from master
- may operate on new and old master (graph TODO)
- Make reads a consensus op (expensive)
- Read from majority (expensive)
- Master Lease
- Replicas promise will not elect new leader for lease
- Leader periodically renews lease with majority of replicas
- No other leader can be elected in this time
- Fail-over time?
- Longer lease -> better efficiency, Longer fail-over
API File System Interface
- + Familiar
- + Services want to store data - same service
- Hierarchical name space
- Not completely general
- Only whole file read/write
- no movement across cells
- no dir mod times
- no path-based permission
- no last-access time
- no links
Permanent vs Ephemeral Nodes
- Ephemeral
- Temporary: Only exists when clients has it opened + active session
- Indicates client is alive
- All nodes can have associated locks
- Per-Node Meta-data
- File Handle
Locks
- Exclusive or shared
- Advisory vs Mandatory
- Often used for general resourses
- ignore for debugging or admin
- little benefit to mandatory - assume coop & good devs
Complexities with locks + failure
- P1:
lock; op(x++); unlock - P2:
lock; op(x+=2); unlock - P1 fails after lock + initiation of op (lock aborted)
- P2 acquires lock, begins op, request for P1 arrives -> inconsistency
- Solution 1: Use lock generation
- Seq#
(lock name, node, gen #) - P1:
seq = lock(); op(seq, x++); - server: check if seq is valid, if not, reject
- Seq#
- Solution 2: lock delays
- Lock release() = immediately available to be acquired
- If free due to failure impose lock-delay (minutes) before can be re-acquired
- long enough to cover msg delays
Events: associated with nodes
- File contents modified
- Child node added/deleted
- Lock acquired -> primary elected
- Conflicting lock request -> not used
- Delivered after event
API
open(), close() Not in ZooKeepergetcontents+stat()setcontents() -> content gen# for atomic cmp-and-swap
Primary election
- Notice no primary
x = open("/ls/cell/service/primary", notify_of_changle)
- When receive notification
if (try_acquired(x) == success)
setcontents(x, myaddr);
else
primary = getcontents(x);
- How can client A determine client failed
- Each client of service creates unique ephemeral node
- Client A subscribes to events on parent service
- If client B’s session and client B node deleted, others notified
Read consistency
- When reading after client issue write and server waiting for invalidation
- Read from server
- Old data
- Block read, don’t reply until ack new write
- Read from server