- Also apply to Chubby ZooKeeper
- All requests go to master
- Bad scalability
- High latency when geo-replicate (remote master)
- Sensitive to load spikes & network delay
- Master down -> system down (for a while)
EPaxos
Goal #
- Optimal commit latency in the wide area
- Optimal load balancing across all replicas
- Graceful performance degradation
So… #
- Every replica need to act as proposers
- or else the latency will be high
- imply no leader
- Minimize proposer’s communication with remote
- Quorum composition must be flexible
Key #
- Ordering
- Old: Leader choose order or choose pre ordered command slot
- EPaxos: dynamic & decentralized
- Not necessary to enforce a consistent ordering for non-interfering commands
- Non-interfering
- 1 RTT
- Need fast-past quorum of node $F + \lfloor\frac{F+1}{2}\rfloor$
- $F$ = min# tolerable node failure
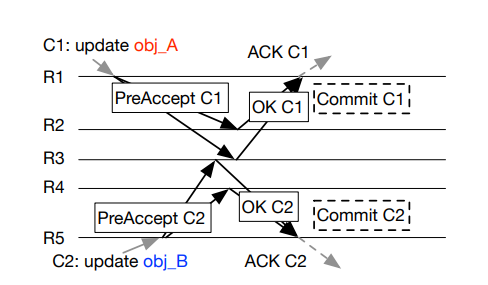
- R1: PreAccept C1
- R5: PreAccept C2
- R2, 3, 4: OK => Commit
- Interfering
- 2 RTT
- quorum size $F+1$
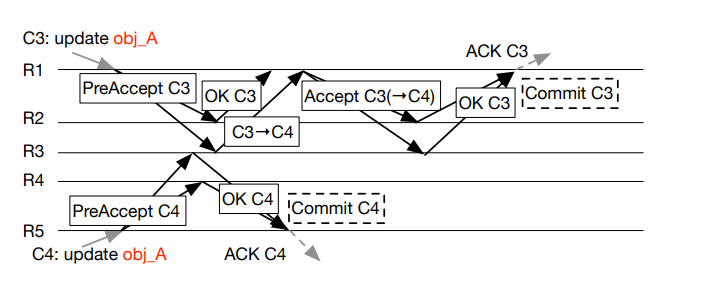
- R5: PreAccept C4
- R3: OK C4
- R1: PreAccept C3
- R3: OK C3 should go after C4
- R1: Receive inconsistent response, second phase
- R1: Accept C3 -> C4
- R 2 3: OK, Commit
Protocol
Commit Protocol #
- (Unoptimized version, fast-path quorum = $2F$)
- Replica $L$ receive a request
- Replica choose the next available instance
- Attach attrs
deps: list of all instances that interfereseq: number for breaking dependency cycles, larger than max(seq deps)
- Replica forwards command and attr to at least fast-path quorum of nodes (
PreAccept) - If quorum responds and attr same => commit
- else update attr (union
deps, set max seq)- => tell simple majority to accept
- => commit
Execution Algorithm #
- find strongly connected components
- topo sort
- bla bla bla
- Paper 4.3.2
Misc #
- Can Limit dependency list size
- dependencies might be transitive
- if not, check during execute
- Failure
- if timeout while waiting for an instance
- send Explicit Prepare
- learn the result or takeover instance and commit no-op
- Replica will be given new id after crash (4.7)
- Prioritize completing old commands over proposing new commands
In class
Motivation #
- Most consensus algorithms have clients communicate with single stable leader (as long as no failures)
- Performance bottleneck
- Handling all client req
- comm w/ all followers
- Extra latency if leader is remote
- Load spikes
- Not available when leader has failed (until fail-over)
Goal #
- Optimal commit latency in wide-area when tolerating 1 or 2 failures, under realistic conditions.
- workload
- how many conflicting ops?
- bursty, timing, exact distance
- environment
- Uniform load balancing across all replicas
- Graceful performance degradation when replicas are too slow
Key Ideas #
- Non-conflicting ops can be committed independently (order doesn’t matter)
- E.g.
- C1 : b = 5
- C2: a= 6
- => commit + execution order does not matter
- Order commands dynamically and in decentralized fashion
- While choosing (voting) cmd for an instance each participant attaches ordering constraints
- Guarantee all commit …
When do commands interfere #
- Tow cmds a + b interfere if there exists some sequence such that
a, b != b, a result in - different state machine
- different read results
- How to determine?
- Data
- Key-value: (Same key?)
- Database: (Same row?)
- Explicit
- Everything conflict
When can fast path be taken #
- If no dependency exist
- If same dep list on all replicas
If no replicas have failed
What if dependency list differs? #
- Run Paxos-accept
- Union of all dependency
How to know when can execute a cmd?
How can client know when cmd is executed? #
On client ACK- To read state, send cmd that interferes with prior state
- will be forced to be ordered afterwards
How many replicas should leader send to? #
- Assume need to hear back from 3
ALL #
- + If some are slow, still hear from 3
- - Lots of extra comm. msgs
Min for fast path #
- + Send min. comm.
- - Slow or dead -> need re-send
Thrifty #
- Send to min but aggressively send more if reply limit received in some timeout
- Does not effect safety
What is bad about reads in EPaxos? #
- Order + execute all prev. conflicting commands
- Other systems:
- Leader/Chubby/Chain:
- - send all to leader, not scalable
- + Linearizability
- ZooKeeper:
- Better scalability, less consistency
- Read lease
- Temporary stable leader for that object
- writes must go thru this lease holder
What workloads do they use? #
- Key-value store
- Update/puts only
- No need for read lease
- Vary amount of conficts
- No eval of cost of determining conflicts
What workloads should they use? #
- YCSB
- common
- synthetic
- well-defined
- allows comparisons
- EPaxos: 100% conflicts ok on 3 but not 5
- Generalized Paxos
- Even fast path needs 3, more TY on conflicts
- Mencius:
- Well: balanced
- Not well: not balanced
Throughput #
- No slow nodes => compare throughput
- Does adding more replicas improve throughput?
- One slow node
- multi-paxos: only leader matters
- mencius
- epaxos