Assumptions #
- Component failures / Fast Recovery
- Optimize for large files
- Large streaming read / small random reads
- Large sequential writes
- Atomic append
- High bandwidth
- Latency => not as important
Architecture #
- Single master server, multiple chuckservers
- chunk
- chunkhandle - assigned by master
- store chunk on local disks as Linux files
- chunk replicated on 3+ servers
- master
- maintains all metadata
- (ACL, file <-> chunk mapping, location …)
- garbage collect, lease management …
- Operation
- Client sends (filename, chunk index) to master
- Master replies (chunk handle, server location)
- Client goes to chunk server
- file and chunk namespaces
- file <=> chunks mapping
- locations of each chunk’s replicas
- store in memory
- 1, 2 persisted on disk
- 3 ask chunkservers on startup
Consistency Model #
- Record append
- appended atomically at least once
- Client cache chunkserver location
Order #
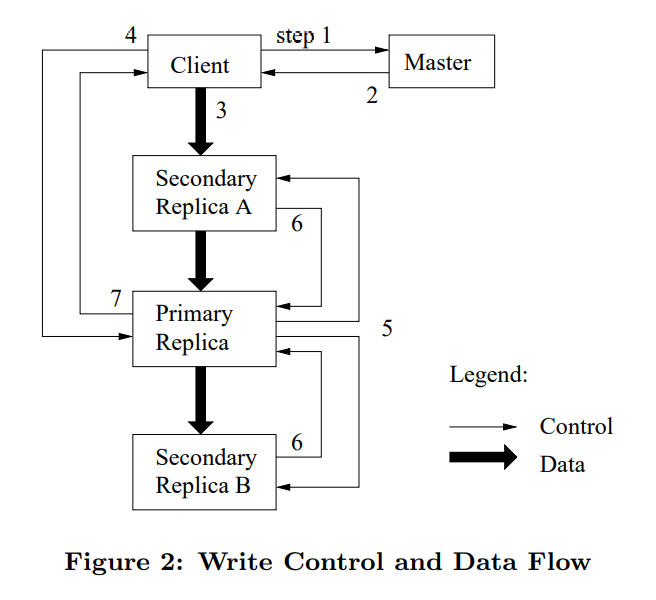
- Order within the same chunk across different servers
- Master give chunk lease to a primary replica
- Primary picks serial order for all mutations
Snapshot #
- Copy-on-write
- Client sends snapshot request to master
- Master revokes leases
- Master duplicate metadata
- Client wants to write C, ask master for replica location
- Master pick new chunk handle C'
- Ask all replica to create C'
Garbage Collect #
- Soft delete (Rename file)
- Collect garbage in background
Stale Replica Detection #
- Assign chunk version number whenever master grants new lease