Reusable Infrastructure for Linearizability
- At least once => exactly once
- Assume system with RPC
- Underlying RPC provide at-least-once semantics
- Not abort after server crash
Architecture
- RPC ID
- Assigned by clients
| ClientID | Seq number|
- Completion record durability
- RPC ID + result
- atomically create with update
- Retry rendezvous
- Retry must replied with previous result
- Might retry from another server
- => need to ensure completion record are there
- Store/Move completion record with associate object
- Garbage Collection
- Server can remove completion record when:
- Client ack server response
- Client crashes
- Server can remove completion record when:
- Lease
- Each client has private lease
- Client ID = Lease ID
- Client crash => Lease expire => reboot => new client ID
Design Detail
- Server upon receiving an RPC =>
- Check duplicate
- Normal case:
NEW- Execute RPC
COMPLETED- return old result
IN_PROGRESS- discard or notify client
STALE- retry msg get delayed after client ACK
- return error
- Normal case:
- Create Completion record
- RPC ID, Object ID, result
- create atomically with update
- mark
COMPLETEDand persist on disk before return
- Client receive reply
- Client mark this seq num as completed
- On next RPC call:
- Piggyback min incomplete seq number
- Server garbage collect item with smaller seq number
- Check duplicate
- LeaseServer
- Zoo Keeper
- Scalability
- Don’t store lease expire time on disk
- (Only the existence of lease)
- Validation
- Lease server implements
cluster clock - Client get clock value when renew lease
- include clock in RPC call
- Server checks lease server if lease close to expire
- Lease server implements
Transaction
- Use RIFL for
requestAbort&prepare
Normal case
- Client send
preparefor each object’s server (participant) - Servers acquire object locks
- return
PREPARED,ABORT
- return
- Client send decision
Client Crash
- First participant become recovery coordinator
- Send
requestAbort(with same RPC ID as prepare) - Receive
PREPARED(Already prepared)ABORT - Coordinator send decision
Garbage Collect
- Client only mark
preparecompleted after receivingdecsionresponse
Occult
- Prevent slowdown cascades
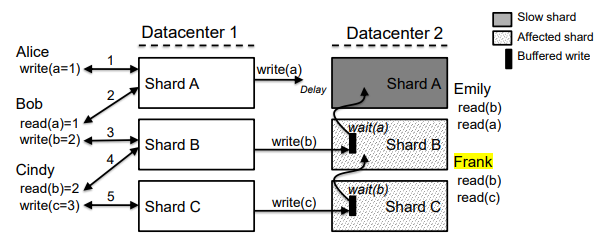
Observable Causal Consistency
- Old: Evolve data store only through monotonically non-decreasing update
- Occult: Let clients decide when to read safely
Framework
- Key-Value store
- Divided to shard
- A master server per shard, multiple slaves
- Client write to master, read from any
shardstampfor each shardcausal timestamp= vector of shardstamp
Write
- Client attach causal timestamp, send to master
- Master increase shardstamp, stored with new value, return
- Client update its causal timestamp
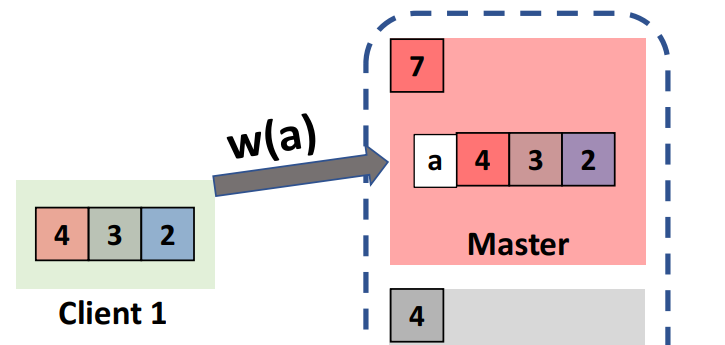
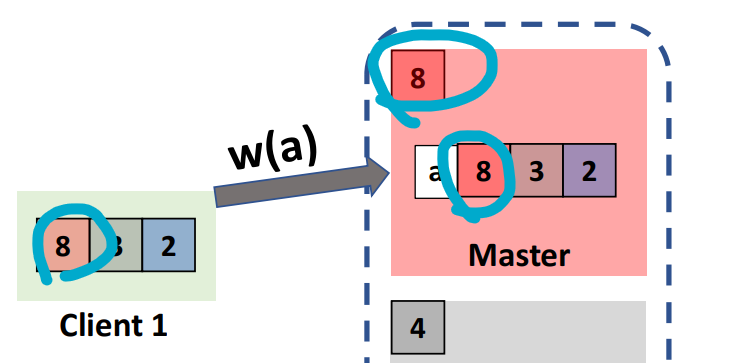
Read
- Server return value and causal timestamp
- Client check if greater than local timestamp
- If no => retry or go to master
- Client update local timestamp
Transaction
Guarantees
- Observe a consistent snapshot
- no write-write conflicts
- transactions in the same client session must be totally ordered
Protocol
to execute a transaction $T$
- Read phase
- Read every object
- ensure not stale (clock)
- Add to read set
- Write
- buffered in $T$’s write set
- Read every object
- Validation phase
- Check if each object in read set is pairwise consistent
- Contact master and request locking objects in write set
- master return object’s causal timestep
- new shardstamp
- client stores in overwrite set
- Check if read set is at least as recent as overwrite set
- Commit phase
- Calculate max timestamp
In class
Solving Linearizability
Single copy (All read/write go to master)
Fail if network partition
- Leader ping
- Leader lease
Need Single-copy & exactly once
Trade-off between amount of concurrency + server state