- Values for each single column are stored contiguously
- CPU faster than IO => Use CPU to save disk bandwidth
- Compress data (e.g. 1 => Wisconsin, 2 => Texas)
- Densepack values (e.g. pack N values each K bits into N*K bits)
- C-Store physically stores a collection of columns, each sorted on some attribute
- can store overlapping projections => improves performance and redundancy
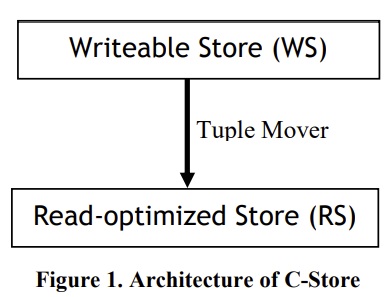
- Insert: Write to WS, batch move to RS
- Delete: marked in RS, purge later
- Update: insert + delete
- Read: historical mode
- query select a timestamp
- return the correct answer as of that timestamp
Data Model #
- Logically still tables
- Store projections
- Tuples in a projection are stored column-wise
- sorted on the same sort key
- Horizontally partitioned => each segment is associated with a key range

- When Query:
- Join multiple segments

- Key: Storage key
- RS: index in the column
- WS: stored as int, larger than the largest in RS
- SID: Segment ID
- Colocate join-index with EMP3(Sender) and partitioned in the same way
RS #
- Use multiple different encoding tricks
- Storage key is not stored (Index)
WS #
- No encoding
- Store storage key
Update #
- An insert is represented as a collection of new objects in WS
- All inserts corresponding to a single logical record have the same storage key
- Keys in the WS will be consistent with RS storage keys because we set the initial value of this counter to be one larger than the largest key in RS
Snapshot Isolation
Insertion vector #
- contains for each record the epoch in which the record was inserted
Deleted record vector #
- contains the delete time for each tuple
Tuple Mover #
- Find segment with modify time at or before LWM (Low Water Mark lowest time user can execute queries)
- if deleted => discard
- else => move to RS
- Write to new RS’ segment
Questions #
- Type 3 encoding save space, not int
- 1:1 mapping between RS and WS?