Memory access cost
Simulating simple scan #
- Linear scan memory,
ptr += stride size every time - If stride cannot fit in cache => slower, worse for newer machine
Data Structures #
- Goal: Reduce stride width
- Solution: Vertical Fragmentation
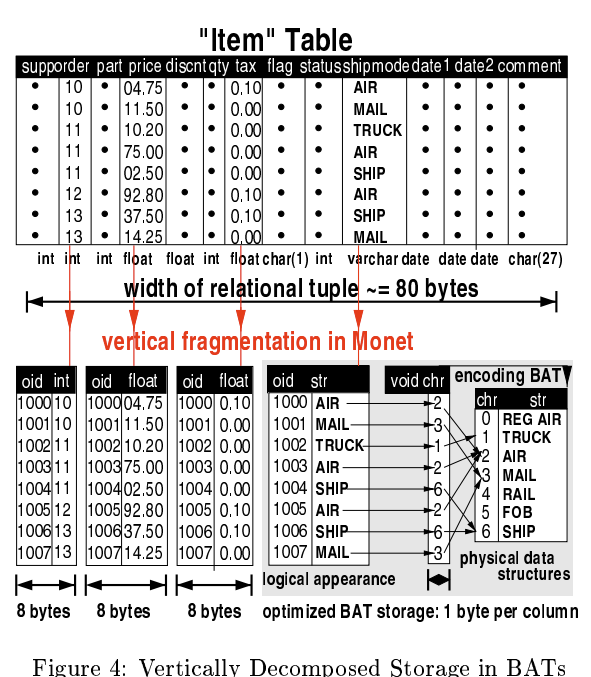
Algorithm
Select #
- Hash table -> Cache unfriendly
- B-Tree -> Better
GroupBy/Join #
- Sort/merge -> Random ops in sort -> Cache unfriendly
- Hash -> need to keep hash table in L2 cache
Radix join #
radix-join(L, R, H [how many cluster]):
radix-cluster(L, H)
radix-cluster(R, H)
FOREACH cluster IN [1..H]
nested-loop-join(L[c], R[c])
- Radix cluster:
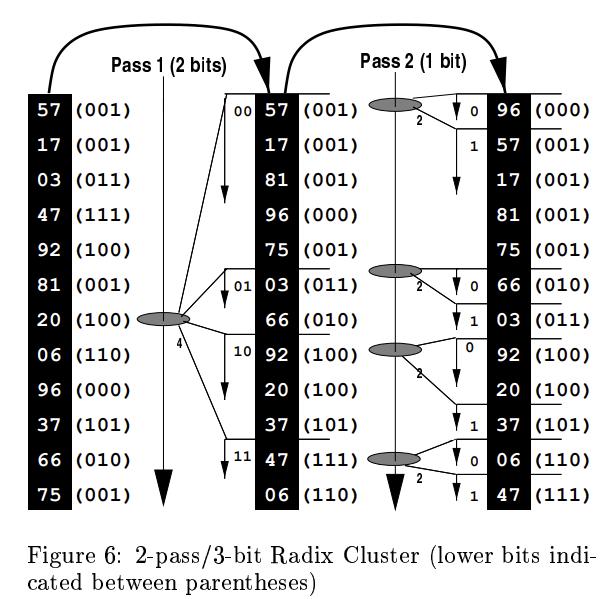
- Take lower $B$ bits, use $P$ passes, $B_p$ number of bits per pass
Questions #
- What is a Binary Units (BUN)